윤종인 개인정보보호위원회 위원장 [사진=개인정보보호위원회 제공]
국내 출시 후 빠르게 인기를 얻었으나, 개발사의 무분별한 개인정보 처리로 올해 초 서비스가 중단된 대화형 인공지능(AI) 챗봇 '이루다' 관련 사태의 재발 방지 장치가 마련됐다. 민간기업이 AI 서비스 개발과 운영 간 발생할 수 있는 개인정보 침해를 스스로 예방하기 위한 안내서가 발표됐다.
개인정보보호위원회는 산업계의 의견을 수렴하고 전문가·전체회의 논의 등을 거쳐 'AI 개인정보보호 자율점검표(개발자‧운영자용)'를 공개한다고 31일 밝혔다. 이 자율점검표는 기업이 AI 설계와 개발·운영 과정 단계별로 개인정보를 안전하게 처리하기 위해 지켜야 할 개인정보보호법 상 주요 의무·권장사항을 알기 쉽게 안내하는 책자다.
안내서는 업무처리 전 과정에 지켜져야 할 AI 관련 개인정보보호 6대 원칙(적법성, 안전성, 투명성, 참여성, 책임성, 공정성)과 단계별 16개 점검 항목, 54개 확인사항을 함께 제시했다. 개인정보위는 AI의 대규모 개인정보처리 특성(복잡성·불투명성·자동화·불확실성 등)을 고려해 안내서에 국제적으로 통용되는 '개인정보보호 중심 설계(PbD·Privacy by Design)' 원칙과 작년말 발표된 정부의 'AI윤리기준'을 반영했다.
AI 서비스 기획·설계 단계에 PbD 원칙을 적용하고 개인정보영향평가를 수행하도록 했다. PbD 원칙은 제품과 서비스를 개발하면서 개인정보처리 전체 생애주기에 걸쳐 이용자의 프라이버시를 고려한 기술과 정책을 반영하는 원칙을 뜻한다.
서비스 개발과 운영 간 개인정보 수집시 적법한 동의, 동의 이외의 수집근거 확인, 공개된 정보 등 정보주체 외의 데이터 수집시 유의사항을 점검하도록 했다. 신규 서비스 개발을 위한 개인정보 수집 동의시 '○○ 서비스의 챗봇 알고리즘 개발'과 같이 목적을 구체적으로 작성하고 이용자가 이해·예측할 수 있도록 '신규 서비스'의 의미를 구체적으로 알려야 한다고 강조했다.
수집된 개인정보를 목적에 맞게 서비스에 이용·제공하고, 동의 없이 '가명처리'해 활용할 경우 개인정보보호법에서 허용하는 과학적 연구와 통계작성 등 범주에 해당하는지, 관련 기준에 맞는지 점검하도록 했다. AI 학습용 데이터로 활용하기 위해 개인정보를 가명처리할 때의 유의사항으로 "SNS 대화 데이터의 경우 발화자의 식별정보뿐아니라 특정 개인의 식별가능정보 또는 사생활 침해 우려 정보도 가명처리가 필요"하다는 점, "가명정보를 불특정 제3자에게 제공(공개 등)하는 것은 사실상 제한되므로 익명처리가 원칙"이라는 점도 명시됐다.
보관·파기 단계에는 개인정보 유출과 노출 사고나 해킹을 방지하기 위해 안전조치를 점검하고, 개인정보가 불필요해지면 안전하게 파기하도록 했다.
AI 개발·운영과정에서 직원의 실수 또는 고의로 개인정보 침해가 발생하지 않도록, 서비스 관리·감독 간 개인정보 취급자와 개인정보 처리업무 수탁자에 대한 관리·감독을 수행하도록 했다.
서비스 이용자를 보호하기 위한 방안으로 개인정보 처리방침에 처리내역을 공개하고, 개인정보의 열람·정정·삭제·처리정지 등 정보주체의 권리보장 절차를 마련해 이행하도록 했다. 이와 더불어 기업이 개인정보 유출사고에 점검내용을 제시했다.
AI 기술 발전과 서비스 등장에 따른 개인정보 침해 예방을 위해 자율적인 개인정보 보호활동을 수행하도록 권장했다.
또 사회적 차별·편향이 최소화되도록 점검하고 윤리적 문제에 대한 판단시 AI 윤리기준을 참고하도록 했다.
개인정보위는 올해 1월 12일부터 4월말까지 스캐터랩을 조사해 이루다 AI 개발과 서비스 운영 과정에서 이용자 개인정보를 이용한 방식이 수집 목적을 벗어났고, 불특정 다수에 가명정보를 제공하면서 특정 개인을 알아보기 위해 사용될 수 있는 정보를 포함해 '개인정보보호법 제28조의2제2항'을 위반했다고 판단했다. 또한 서비스 개발에 데이터를 활용하면서 해당 정보주체가 이를 명확히 인지할 수 있도록 알리고 동의를 받지 않았음을 확인했다.
스캐터랩은 자사 앱 서비스 '텍스트앳'과 '연애의 과학'으로 수집한 이용자의 카카오톡 대화 데이터를 작년 2월부터 올해 1월까지 별개 서비스인 '이루다'의 AI 개발·운영에 이용했다. AI 모델 학습을 위해 60만명의 카카오톡 대화 94만개 문장 속의 이름·전화번호·주소 등 개인정보 삭제와 암호화 조치를 하지 않았다. 운영 과정에는 AI의 응답용 문장 데이터베이스 구축에 20대 여성의 카카오톡 대화 문장 1억건을 이용했다. 2019년 10월부터 올해 1월까지 코드 공유 협업 사이트 '깃허브'에 AI 모델을 게재하면서 성을 제외한 이름 22건, 구·동 단위 지명정보 34건, 친구·연인 등 대화 상대방과의 관계가 드러난 카카오톡 대화 문장 1431건을 포함시켰다.
이번 자율점검표는 스캐터랩 제재 처분을 "기업이 스스로 관리·감독을 강화해 나가는 계기"로 삼기 바란다던 개인정보위가 AI 기술 기업의 올바른 개인정보 처리 방향을 제시하기 위해 만들어진 것이다.
이날 개인정보위는 AI뿐아니라 다양한 ICT 서비스 개발·운영에도 자율점검표를 활용할 수 있으며 자율점검표가 신기술 분야의 개인정보 침해요인을 예방하는 데 도움이 될 것으로 기대한다고 밝혔다. 자율점검표 보급을 위해 6월 초부터 AI 스타트업 대상 설명회를 개최하고 중소기업 컨설팅과 교육에 활용할 계획이다.
윤종인 개인정보위 위원장은 "AI 개발자·운영자가 이번 자율점검표를 적극 활용해 AI로 인한 개인정보 침해를 예방하고, 보다 안전하고 신뢰할 수 있는 AI 서비스 환경을 조성하는데 도움이 되길 바란다"며 "앞으로도 개인정보위는 바이오정보·자율주행차·드론 등 신기술 환경변화에 대응해 현장에서 개인정보가 안전하게 보호될 수 있도록 노력하겠다"고 말했다.
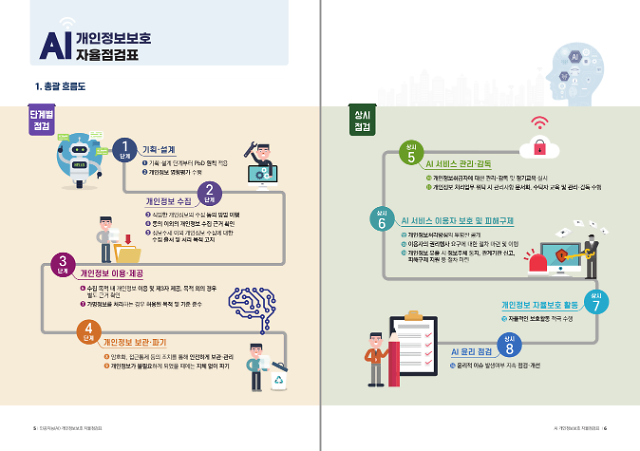
AI 개인정보보호 자율점검표 일부. [자료=개인정보보호위원회]